
DeepSeek新论文被称“硅基生命进化论”,海量文字压缩成图,模仿人脑重塑AI视觉记忆边界,赢硅谷大佬力挺

出品|搜狐科技
作者|郑松毅
DeepSeek再次“低调”震惊世界!
他们新发布并开源的OCR模型,从根本上改变了AI游戏规则。Github开源项目DeepSeek-OCR,一夜收获超4k星。相关论文(《DeepSeek OCR:上下文光学压缩》)解释了这一研究成果。
很多人好奇,什么是OCR?
传统OCR如同“文字扫描仪”,通过光学技术将图像中的文字提取转换为计算机和人都能理解的格式。比如,在将大量票据、证件、表单等数据电子化时,OCR发挥关键作用。
但DeepSeek却反其道而行之——将文本信息“绘制”为视觉图像,再通过视觉模型实现高效理解。如此创新尝试就是为了解决大模型的核心痛点——处理长文本时面临的计算挑战。
效果有多惊艳?10页密密麻麻的文本报告,被压缩成一张图片,AI能够一眼读懂它。这样的信息处理效率意味着大幅降低了计算复杂度,用最直接的方式节约成本。
论文发布后,意料之内的好评如潮,有网友直接将其称为“硅基生命进化论”。
最近还在锐评AI发展的OpenAI创始团队成员、特斯拉前AI总监Karpathy,对DeepSeek新成果直言喜爱,并指出“早就该让视觉成为AI核心,而非依赖烂透了的文本分词器。”
更有业内大佬感叹,“当文本能被转化为视觉可理解的结构,语言与视觉的统一或许不再是理论。这可能是通往 AGI(通用人工智能)的关键一步。”
DeepSeek新研究:把大量文字压缩到图片,让模型直接看图理解
本质上来说,DeepSeek-OCR是将视觉与语言模态深度融合,通过“视觉-文本压缩”建立自然映射关系,为多模态大模型提供了新的技术路径。
展开全文
之前的大模型可以说是“带着脚铐的舞者”,虽有强大的语言理解能力,却被低效的信息输入方式严重束缚。
拿模型阅读长篇文本来说,每页财报、论文都包含数千个token,传统方式下只能逐字逐句识别,导致计算量爆炸。这种低效作业让大模型在法律、金融等领域的应用举步维艰。
而DeepSeek这次用到了一个巧妙思维——既然一张图片能装下成千上万的文字,那是不是大量文字信息也能被压缩到一张图片里,让模型直接看图理解就好了。
为实现这一设想,DeepSeek为OCR模型配备了三件套——图像编码器、映射层和文本解码器。其中,图像编码器DeepEncoder(负责把图片转成高度压缩的视觉token)参数为380M,文本解码器(负责从压缩的视觉token里重建文字)是一个deepseekv2-3b的模型,参数为3B。
整体训练数据由4部分组成,包括OCR1.0数据(传统OCR任务,如图像OCR和文档OCR)、OCR2.0数据(复杂图像解析任务,如几何、图表等)、通用视觉数据(用于注入通用图像理解能力)、及纯文本数据(用于确保模型的语言能力)。
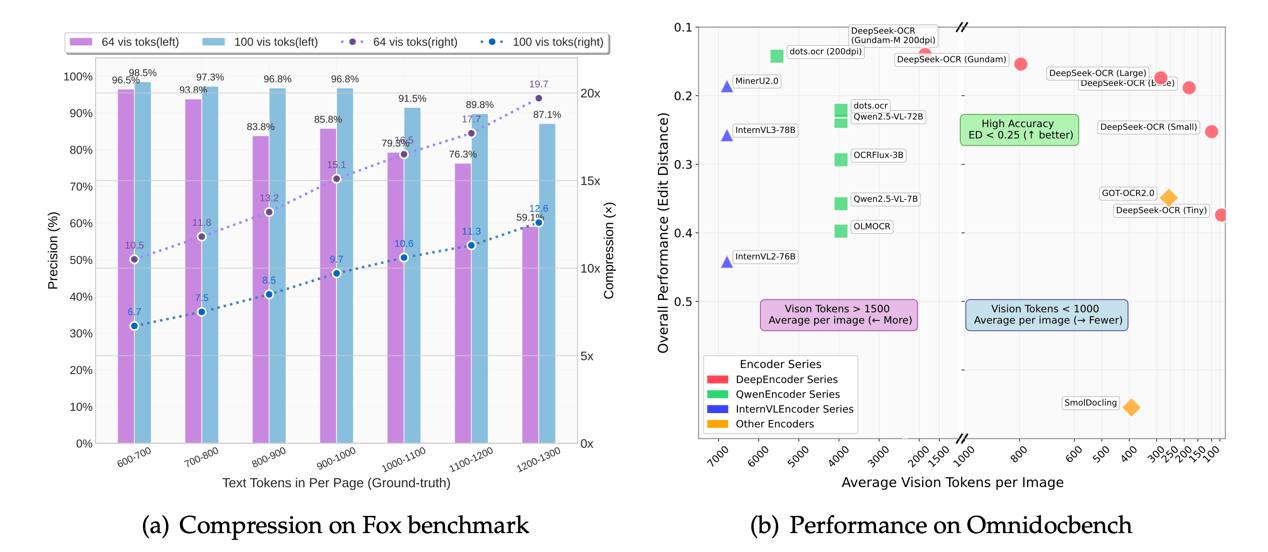
别看模型参数不大,但就研究结果发现,当文本压缩率小于10倍时,模型OCR解码准确率高达97%,及时压缩率高达20倍时,准确率依旧能保持在60%。在A100-40G显卡环境下,单日可生成超过20万页的模型训练数据。
也就是说,如果普通 OCR 需要 10,000 个 token 才能读完整篇文档,这个模型可能只用 1,000 个就能搞定,且能高准确度地理解信息。
受益于训练数据多样性,论文提到DeepSeek-OCR不仅能识别文字,还能理解文档布局、图表结构。从某种角度说,这已经不是传统的OCR,而更接近“文档理解引擎”。
论文中提到的一个基准叫OmniDocBench,就是专门用来测试复杂文档理解能力的。DeepSeek-OCR 在这个基准上,用更少的视觉 token 数量就超过了 GOT-OCR 2.0 和 MinerU 2.0,这俩都是目前较顶尖的开源 OCR 模型,可谓十分能打。
让AI记忆模式更像人类
在论文中,DeepSeek还谈到了一直困扰业界的AI“记忆”和“遗忘”机制。
深度学习模型的记忆以分布式参数形式存储,这种非结构化存储导致传统神经网络在学习新任务时,旧知识的参数空间会被新知识覆盖,模型无法做到像人类一样进行连贯推理。
而DeepSeek的想法是,通过视觉-文本压缩范式和动态分层遗忘机制,让AI“记住该记住的,忘记该忘记的”。
其核心思路是将文本信息转化为视觉token,通过光学压缩实现高效记忆管理,同时模拟人类遗忘曲线动态调整信息留存。
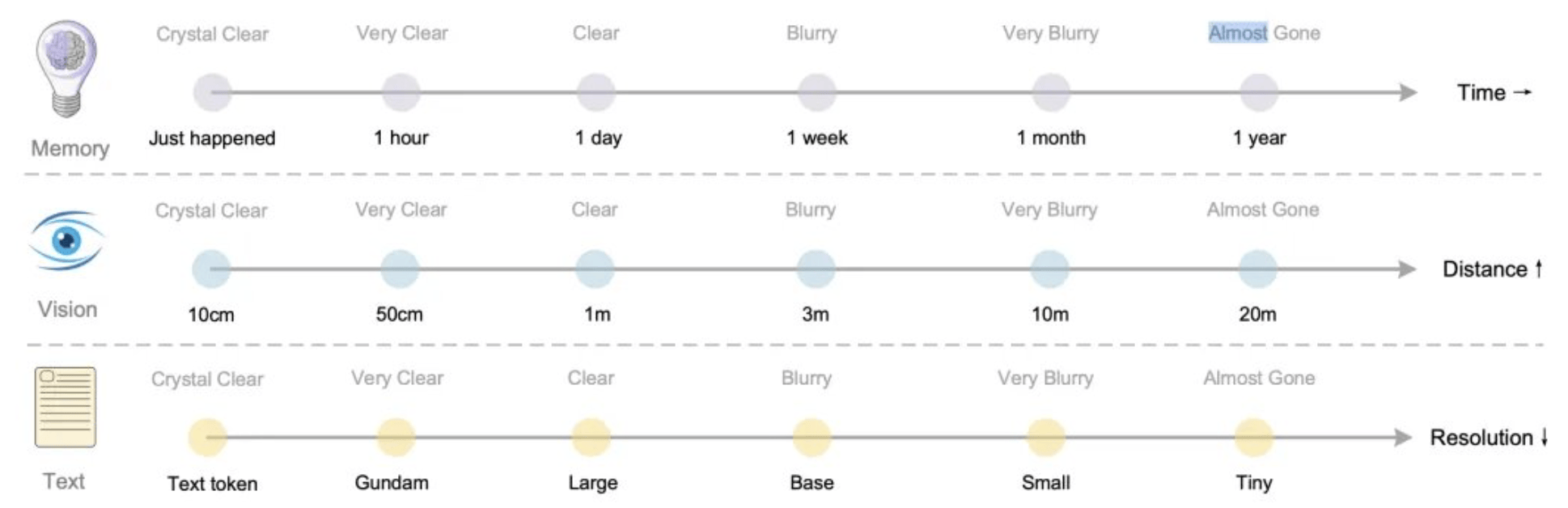
在这个过程中,核心组件DeepEncoder发挥关键作用,50-100个视觉tokens即可还原1000字文本,实现近 10 倍的计算量节省。
这种压缩并非简单的信息降维,而是通过“注意力机制+结构化训练”,优先保留对模型推理最关键的信息。类似人类阅读时“先抓标题再看细节”的认知模式,去除不重要的信息噪声。
关于如何让模型的记忆模式更像人类,研究者做了进一步解释:对于近期记忆,可以将其渲染成高分辨率图像,用多token数量保留高保真信息。而对于远期记忆,可以缩放成更小、更模糊的图像,用少量token来保留信息,从而实现信息的自然遗忘和压缩。
虽然当前还仅是研究前期探索阶段,但DeepSeek的创新思路,确实让AI越来越像人类了。
三名作者
本篇论文共有3名作者:Haoran Wei、Yaofeng Sun、Yukun Li。
论文一作Haoran Wei曾主导开发爆火项目GOT-OCR2.0,此次的DeepSeek-OCR也可以说是延续了此前项目的创新技术路径。根据此前论文信息显示,Haoran Wei还曾就职于阶跃星辰。
Yaofeng Sun毕业于北京大学图灵班计算机科学专业,于2023年加入DeepSeek,先后参与DeepSeek-r1、DeepSeek-v3、DeepSeek-v2等模型的研究。
Yukun Li也参与了包括DeepSeek-v2/v3在内的多款模型研究,谷歌学术论文引用量近万。








评论